
Aeolian Machine Intelligence
A typical wind turbine is equipped with around 100 sensors, each producing 100 datapoints per second. And yet communication can be patchy…

A typical wind turbine is equipped with around 100 sensors, each producing 100 datapoints per second. And yet communication can be patchy, 3G rare. CCTV networks can only afford to send back to the data center a small fraction of the captured videostreams. Robots in a manufacturing plant can sense at millisecond granularity, but the plant’s SCADA infrastructure can handle perhaps 1 observation per minute (with 1 observation per 15 minutes being a typical sampling rate).
This is a very ‘2015’ problem. As the IoT gets more commoditized and high-frequency, one Moore’s law (cheaper sensors) goes against another (cheaper storage) and the outcome is not predetermined: in a large variety of applications it is now necessary to perform data reduction at the edge. Put simply, one reports less frequently than the capture rate, by performing some form of aggregation at the edge.
At Cisco Live in San Diego where we presented our solution for on-the-fly, on-the-edge Machine Learning, an IoX product manager put it nicely: “right now we have devices flooding the network with a constant stream of ‘I am doing OK. I am doing OK. I am doing OK. I am doing OK …’. I’d much rather just hear from them when they are in trouble”. Mentat’s anomaly detection technology can enable fruitful interactions between humans and the tsunami of data from the IoT.
Senior voices joined in during the Executive Symposium panel discussion, where Mala Anand, our Chief Data Scientist and other prominent figures in Data Science addressed the future of data and machine learning. In her concluding remarks, Mala emphasised the need for data reduction on the edge as data sources such as video and high-frequency sensing from the IoT proliferate.

What is it that makes Streaming Edge analytics different from Traditional analytics, or Big Data analytics? There are three main differences :
1. Scale with Velocity (not just Volume). A Hadoop query that runs a little slow is a discomfort; a streaming query that runs too slow is a disaster, resulting either in data loss or a system crash (or both), as new observations pile in waiting to be processed. Moreover, most edge use cases involve the need for real-time actionable insights with short lifespan, where “delayed” is just as bad as “missed”.
2. You can’t store everything. By definition of the use case, some data will be lost. But the information contained in this data need not be lost, if your streaming analytics are done properly. The simplest example is a sum: it is trivial to compute it in a streaming fashion, via a cumulative sum that yields a 100% accurate answer without any data storage. Surprisingly many statistical insights can be extracted in this way.
3. You can’t scale out easily (neither on CPU nor on RAM). Edge computing generally relies on few, small computers. Think 2000. Forget about machine learning techniques that need GPU farms to get started.
These are the constraints we listed on our white board at the South West of rainy London when we set out to design our demo for Cisco Live at sunny San Diego a few months back. And this is what we came up with.

The core idea came easily: we needed to deploy on a Raspberry Pi. These tiny very low cost devices are fairly close to the capabilities of a typical fog node. The Pi would receive a stream of data in one port at high frequency, process it in real-time, and output the resulting analytical insights in another port at a lower frequency.
The challenge for the data replay was to stream the data at the same pace as the original dataset was being saved. In order to do so, we created a small tool coded in Elixir that would read and replay a dataset (CSV format) and re-stream over the network it in real time, re-timing each observation with the current timestamp. The tool would detect the original time delta between two observations and would make sure that we don’t emit a new observation too early or too late.
Since Linux’s Process Scheduler doesn’t give you any guarantee about when your process is going to be put asleep and how long this will last, we made sure to detect and discard any record that would be considered as “too old”.
I/O is the general bottleneck and in our case, reading the CSV dataset from the disk was of course slow. Furthermore, as the Process Scheduler was putting us asleep from time to time, we had to make sure that we had a buffer for the CSV records.
We therefore had a bunch of different Elixir (Erlang) Processes in charge of the entire pipeline: reading the CSV file, transforming each line in a new structured record, retiming the data and coercing some of the values, queuing the records, consuming the queue and streaming the records.
In order to have a clear, visual and realistic demo, we decided to use a second RaspberryPI to run the data-replay tool. This way we could very easily plug and unplug the Ethernet cable that was linking them to stop and resume the consumption and analysis of the data.
Since only part of the team could go to San Diego, we had to make sure that we could still deploy fixes and updates remotely.
We deployed an OpenVPN and a private Docker registry server in AWS to make sure that the technical team could deploy new containers with the latest version of the code and we provisioned the Raspberry PIs with Chef to ease the setup. In just a couple of commands the latest versions were deployed remotely round the world.
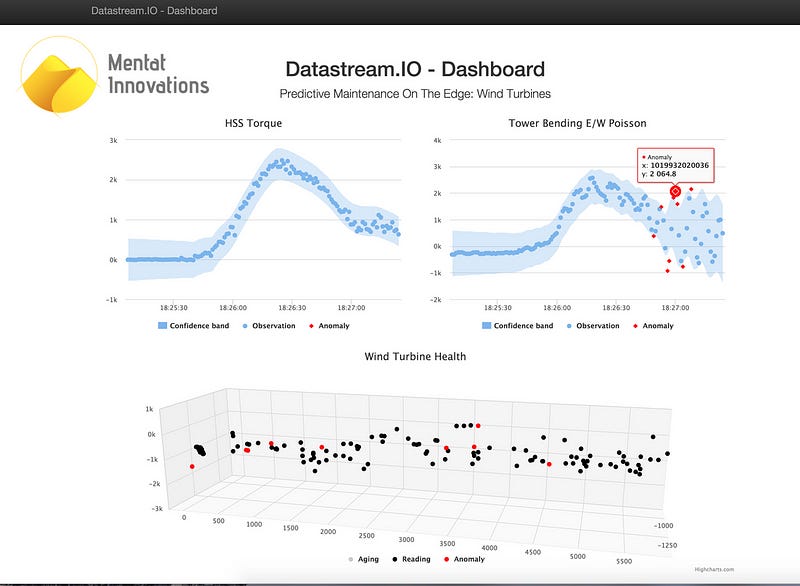
So one Rpi streaming 90 wind turbine sensor readings at 100 Hz each (or 9000 datapoints per second in total) going into our datastream.io core engine running on a single core of the CPU of the second Rpi, which then displayed a custom dashboard built for the demo. Anomalies were detected on all sensor streams in real time and our alert correlation technology gave a holistic view of the wind turbine health.
Originally published at www.ment.at on 13-Aug-2015