
Big Data Privacy
The Mentat team spent six weeks at Level 39 in Canary Wharf, as a finalist at the EY Challenge on privacy. This program inspired us to…

The Mentat team spent six weeks at Level 39 in Canary Wharf, as a finalist at the EY Challenge on privacy. This program inspired us to rethink much of what is currently standard practice in analytics with respect to privacy issues.

Data collection and storage technology is transforming our world. Bicycles are connected to the internet, smartphones will become our personal physicians and cities have already become cashless. A connected world, full of opportunity — a Big Data dreamland. And yet the old paradigm of storing all this data is challenged. The sheer volume sometimes makes it impossible. But a more alarming downside is the potential for privacy infringement. Embarrassing pictures on Facebook are only the beginning. Consider arbitrary third parties knowing your physical location, your habits inside the privacy of your own home. A Big Data nightmare. So is the Big Data dream in danger?
Should we have to choose between Big Data and Privacy?
Let’s get more specific, to remind ourselves of exactly what is at stake. The three big telcos know exactly where every single Londoner is at any given time. A high-street retail chain might be interested to see the demographics of the people walking past its store on a typical Sunday, right now, or even better, tomorrow afternoon, so that they can promote items that appeal to this particular customer segment. Golden third-party sharing opportunities.
Smart metering. The National Grid needs to anticipate demand surges so as to balance the grid as a whole. It only has information accurate down to sub-station. In an ideal world National grid would be able to have information down to the postcode level, ensuring non-storable energy (e.g., renewables) is used optimally and demand peaks are handled efficiently. In an ideal world the utilities would be able to detect daily and hourly patterns of electricity demand at the household level, and offer personalised tariffs that incentivise off-peak consumption. The end product: a balanced grid, cheaper energy for all, and reduced energy waste.
Neither the Telcos nor the utilities are able to deliver this without a huge privacy risk: it only takes one incident to bring down the full force of the law, and irreparably damage the company’s reputation.
The EU has been pushing for tighter legislation around privacy for a while, largely driven by the potential for large-scale privacy infringement by the data behemoths: Facebook, Google and similar organisations plus the governments of this world. The reality though is that even SMEs or an innocent app can cause irreparable damage to an individual if they misuse private information. What is being challenged here is a “tacit agreement” between consumer and digital service providers that has so far served the latter much better than the former: “click here to accept the terms and conditions about data usage”. One click can no longer offer a get-out-of-jail card for the data holder. Consumers that initially give consent to share data now retain the right to change their mind. The EU aptly calls it “the right to be forgotten”, and, let’s be honest, it seems fair. But is it enforceable?
Mentat thinks John Oliver probably has it right : No way !
Private data, once stored outside the confines of your home and personal devices, are at risk. A healthy new ecosystem will no doubt grow around ‘safer data control’ and ‘data provenance’, but the reality is, every lock can be picked, and as the amount of private information being stored and shared increases exponentially, so does the risk of it being abused. So it does seem that Big Data and privacy might be incompatible, after all.
But what if we could think outside that box? What if we could have it all?
We feel the real culprit is a decades-old Business Intelligence practice which we refer to as the “store everything, analyse later” approach. Indeed, the standard workflow of a Business Intelligence unit involves storing everything about everyone in massive data warehouses and pulling reports at arbitrary points in time later to satisfy the appetite of the next internal Powerpoint presentation, or to help determine the next-best-action during a customer service call.
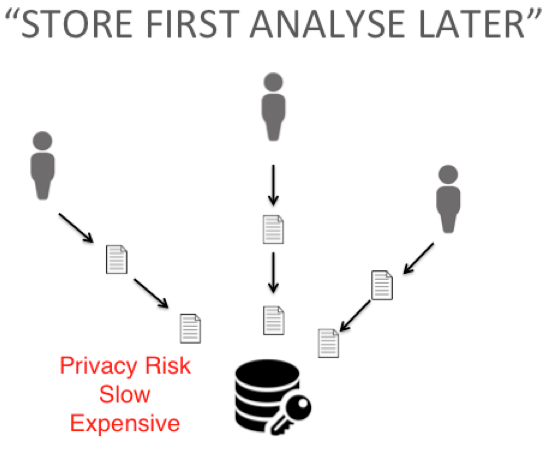
This “keep it, just in case” rationale is outdated, and is, increasingly, seen as offensive, as it rests on an assumption that private data is a free, up-for-grabs resource. This is precisely the viewpoint that is becoming untenable.
At Mentat, we have a different viewpoint. Our cornerstone belief is that “value lies with information, not with data”. Value is derived from actionable insights, which in turn rely on processed information, not on raw data. Of course in some settings, you do need raw data (e.g., for billing or auditing), but in the vast majority of Business Intelligence tasks, it is aggregate insights you want, rather than the private data itself. Well, you are in luck: with streaming analytics technology you can keep the insights, but throw away the data.
So how does it work? A suitable analogy is that of an experienced store manager: they have learnt on the basis of past experience how to judge a character and sell differently, but they don’t remember the national insurance numbers and postal addresses of every single customer they have interacted with. This analogy cuts deep: a learning agent glimpses at new data, and uses it to update their view of the world, without storing every single bit and byte.
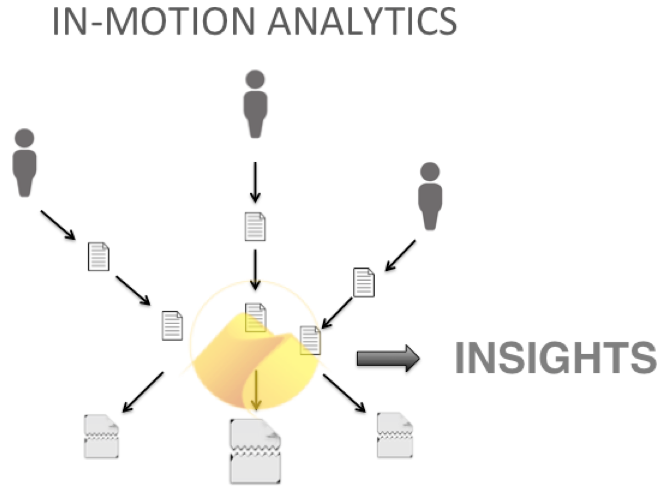
Going back to the use case of the mobility map, we can learn from the data how different customer segments move around the city in real-time, anticipate flows as they propagate — has a tourist bus just deposited hundreds of potential customers on Marble Arch? How likely are they to come near your store? We call this an information asset, in contrast to a data asset. The information asset only ever holds aggregated information, that cannot be traced back to the individual. So it’s not all or nothing: most of the useful insights that you need, don’t actually need the private data to be stored. In an ideal world, you shouldn’t have to face dilemmas like this one.
Smart metering. We define our information asset: a geographical predictive map of energy demand patterns in real-time, down to the lowest granularity that allows anonymity: e.g., the first half of the postcode. The techniques we use are compliant: they rely on the same principles used by, say, the Office for National Statistics. But our reports are real-time, so that National Grid has time to act and match demand and supply.
The same principle applies to any personal device in the Internet-of-Things. Privacy risks associated with wearable health sensors connected to smartphones will dwarf the risk of smart metering data. It is critical to rely on information assets that are privacy-respecting. Imagine a real-time map of asthma attacks in the city of London, split by age-group, offering warnings to individuals at risk.
Make no mistake: the digital economy will look different in one or two years from now, and privacy-enhancing service providers will need to introduce an array of technologies to ensure their data-driven business models remain intact while respecting consumer privacy. Better authentication systems, or smarter data management solutions, like our fellow EY challengers Sedicii and Exonar will no doubt be part of the solution. But when it comes to business analytics, forward-thinking companies that embrace the empowering technology of on-the-fly aggregation using in-motion analytics will proudly gain the reputation of respecting not only the letter, but also the spirit of the law: private information will be glimpsed at, to ensure that consumer and service provider alike benefit from the Big Data value chain, but it will then be forgotten, literally milliseconds later. That’s what drives us at Mentat: true innovation, which can helps us break free of false dilemmas.

Originally published at www.ment.at on 8-Jan-2015