
datastream.io
Robust Anomaly Detection at Scale

Robust Anomaly Detection at Scale
One of the core competencies of the Mentat team has been anomaly detection, in particular unsupervised streaming data anomaly detection.
Anomaly detection (also known as outlier detection) is the identification of items, events or observations which do not conform to an expected pattern or other items in a dataset. These events may indicate network intrusions, industrial component failures, financial fraud or health problems.
Classifying anomalies correctly and efficiently determines the usability and effectiveness of many algorithms. It is a horizontal technology that is core to data driven methodologies.
Googling for anomaly detection we find the Twitter R package with almost 2300 stars at github at the top. We were tempted to test that approach with a subset of our anomaly detection models for benchmarking on the same dataset. We have been working on a set of tools for scalable streaming anomaly detection under the project name datastream.io or dsio for short.

Given the unsupervised nature of the problem in a streaming context we need to take into account the following complications:
Without labels, we must rely on a model of normal behaviour.
All models of normal behaviour make assumptions about the data.
It is important to make these assumptions robust to common sources of variation.
Periods
Periods are a common problem in anomaly detection: the natural fluctuation of the data means that it might not be as easy to detect local anomalies (for example, peaks that fall within the periods of the data). Overcoming this problem was a flagship property of the Twitter AnomalyDetector package:

Here we illustrate the anomalies detected by the Twitter package and our own detector, part of which will be open-sourced soon. Happily, they largely agree, and are both able to detect local outliers even when these lie within the normal range of the data.
Period shifts
However, anyone who has worked with real data will know that sometimes periods shift … This might not be true in calendar-driven events where periods are forced by day/week/month/year patterns, but, for example, in industrial IoT devices it is extremely common: deactivating a component for a little while, or pausing a drill, will cause an otherwise periodic signal to shift its period. Frequency-based methods such as Fourier Transforms are very confused by such behaviour. It turns out, so is Twitter’s method, if we shift the period mid-way by 1000 steps, and results in reporting a much greater number of anomalies, most of which are false alarms resulting from the introduction of bias into the estimate of the period by “pausing” the periodicity for a very short period of time, just once:
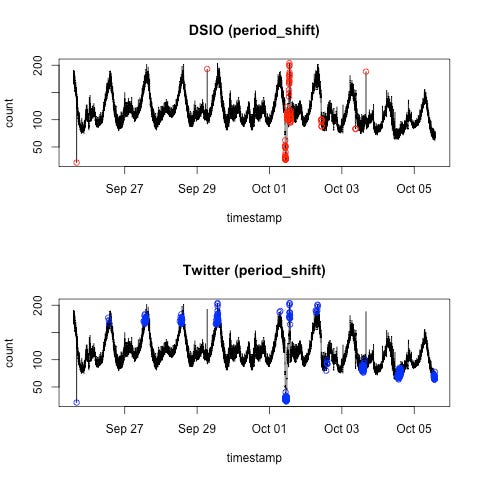
In contrast, our detector is not confused at the least and continues to flag the same anomalies.
Another way in which data can fool you is by the introduction of a trend. Although there are several techniques for de-trending time series, the point we are trying to make here is that a real-world generic anomaly detector should be robust to such disturbances without the user having to take special precautions according to the use case. Twitter’s detector is confused by the introduction of a trend, and ends up reporting no anomalies at all, whereas datastream.io remains stable:

Yet another way to get confused is when the signal suddenly jumps to a new mean level — a very common occurrence in real-world data, like in the case of a web server which suddenly becomes more popular due to a successful marketing campaign. This shift is handled poorly by Twitter’s AnomalyDetector package, which results in removing all anomalies from its report, as an (exaggerated) reaction to the increased range of the time series. Yet again datastream.io remains stable:

Conclusion
Looking at this simple univariate problem its easy to see there is significant room for improvement in the anomaly detection space. We have argued elsewhere and continue to argue here that robustness is the secret sauce that makes machine learning methodology truly generic and hence usable in the real world. Put differently, it increases the ROI of any investment in machine learning projects, because it reduces drastically the biggest cost: the amount of data preprocessing, cleaning and custom modelling that the data scientist needs to do before they can deploy their favourite method. That’s what datastream.io is all about: robustness.
We will start open sourcing some components of the stack and we are looking to create a community around robust anomaly detection, bringing together startups, researchers and practitioners. Feel free to reach out to us here should you want to be involved.